
type
status
date
slug
summary
tags
category
icon
password
1.用户画像平台该如何建设?
根据上一篇文章,我们讲到用户画像其实就是用户的标签或者特征,首先要明确就是要完成标签的生产和加工,那么涉及到的内容就包括数据的接入、清洗、和最后标签的加工入库。
标签整体流程如下:
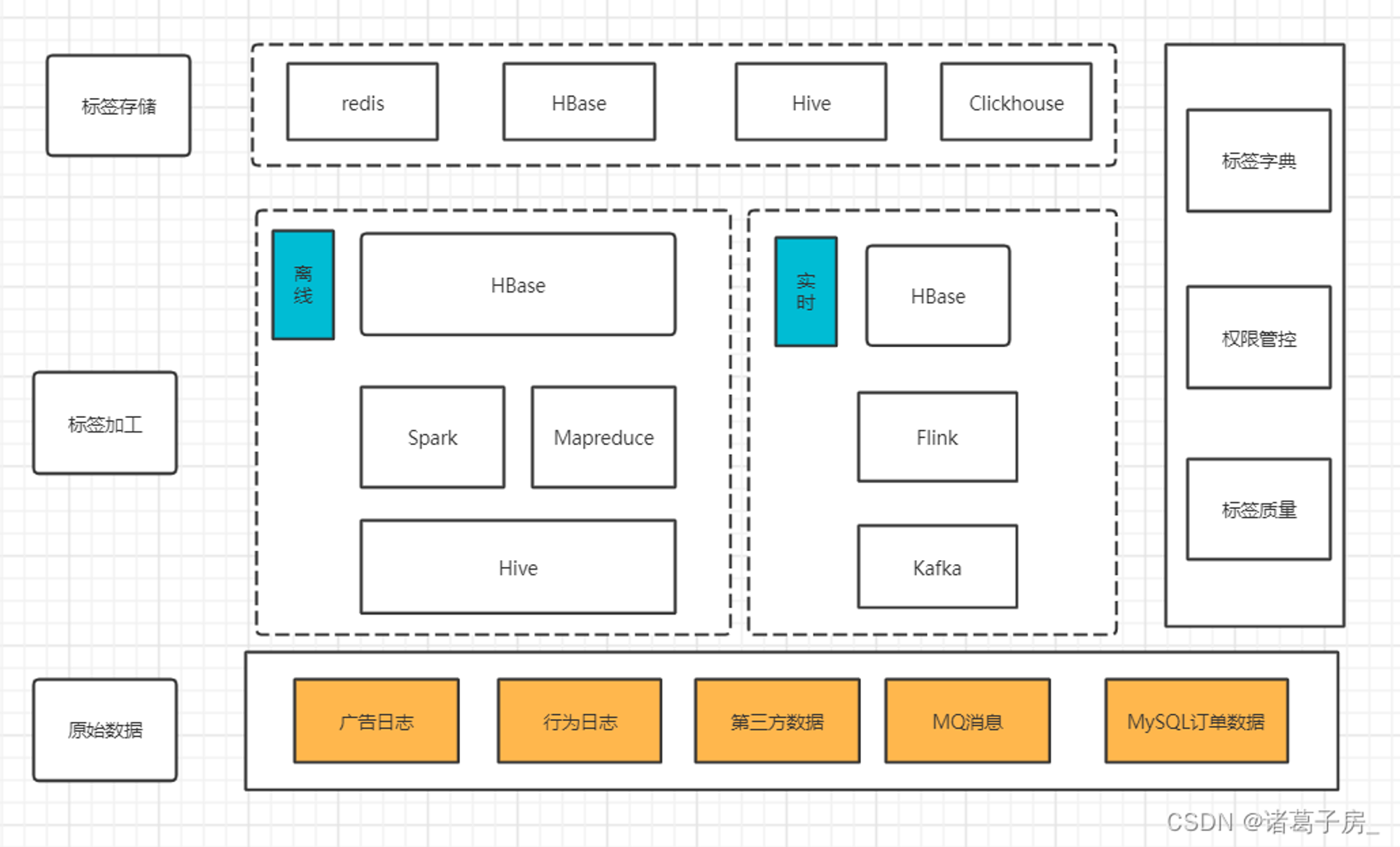
(1)线上日志数据接入和处理
数据分层
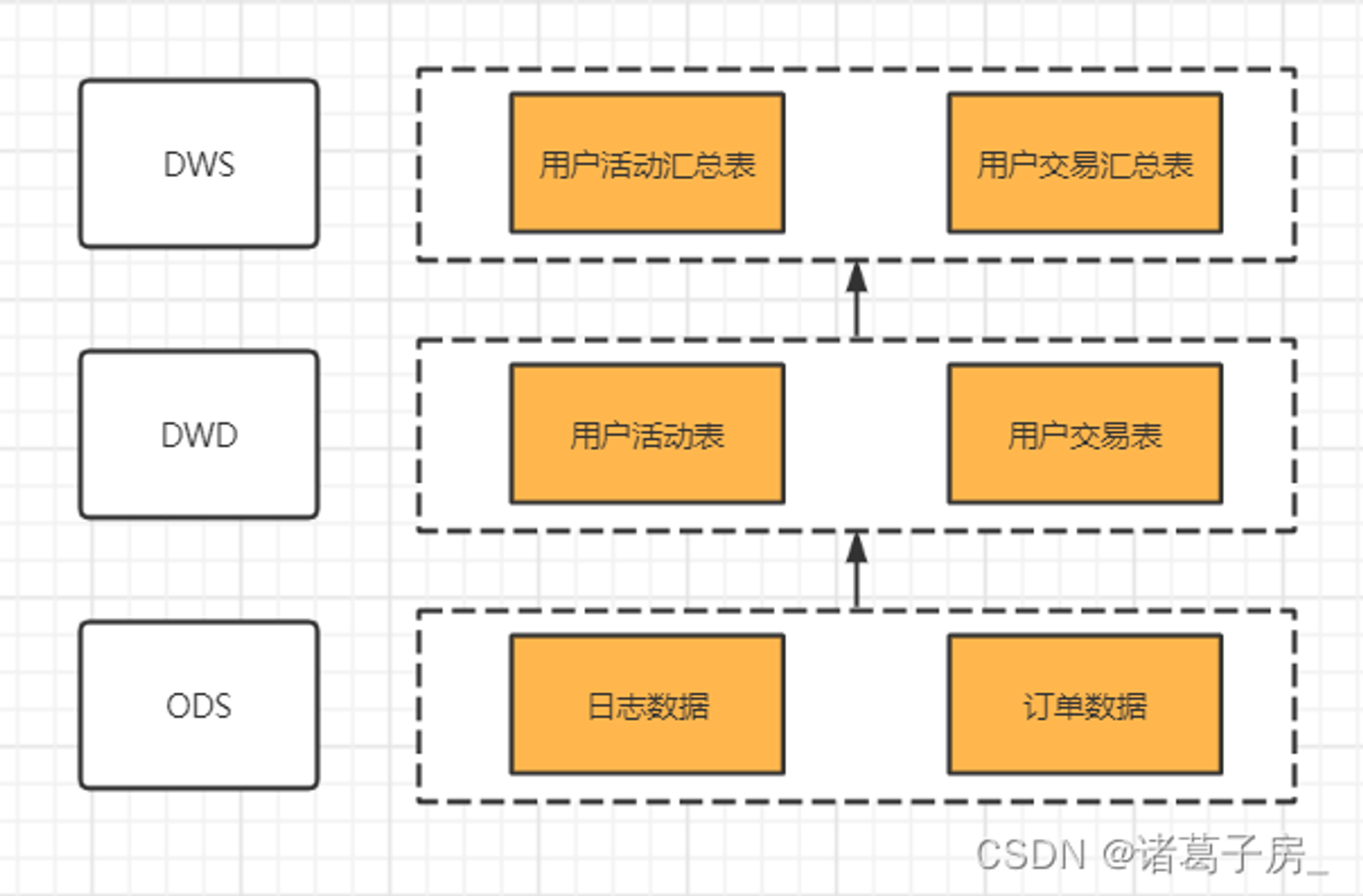
(2)标签的加工和挖掘
a.标签加工根据标签的加工方式分为三类:事实类、统计类、算法类
事实类:主要是基于原始数据同步过来即可,比如:最后一次登录时间
统计类:在原始数据上做一些简单的统计规则,比如:最近一个月活跃天数
算法类:根据用户的行为和交易信息利用算法挖掘出来,比如:工作位置、家庭位置(根据gps信息采用聚类算法挖掘出来)
b.标签加工根据标签的时效性分为三类:离线(T+1)、准实时(T+H)、实时
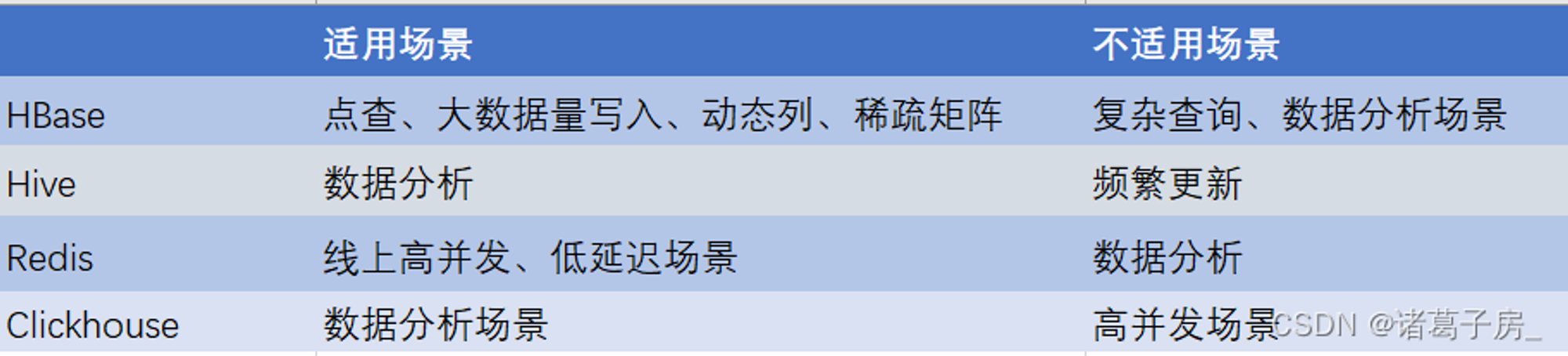
(3)标签存储和应用
为了应对不同的应用场景,使用不同的数据库作为存储方案
(4)标签权限管控、标签字典、标签质量
标签权限管控:业务只能使用申请权限了的标签权限,标签权限配置存储在MySQL
标签字典:标签内容数据只存储字典枚举,而不实际存储实际内容(比如:性别标签男女存储为0、1)
标签质量:对于标签的数据质量进行监控、波动告警,包含:标签的覆盖率、标签分布的监控告警
2.用户画像建设过程中会用到哪些技术?
(1)大数据相关的一些技术
Java、MySQL、Python、Hive、Spark、Flink、HBase
(2)服务开发
rpc服务
(3)标签挖掘算法
聚类、逻辑回归等,Python、Spark
3.用户画像建设过程中会遇到哪些问题?
(1)降本增效大环境下,用户画像侧如何做好存储和计算性能优化?
a.KV存储采用Protobuf存储,Protobuf编码性能好且压缩比高。因为画像的数据类型一般比较固定、单值或者多值,对序列化反序列化性能以及数据压缩效果有较高要求
b.标签内容字典化
c.画像特征抽取自定义抽取,资源占用低
目前特征抽取主要有单特征抽取和批量特征抽取
单特征:优点,控制灵活。缺点,每个特征都会启动各自的拉取任务,执行效率低且耗费资源。
批量特征抽取:成本可控,但较依赖上游Hive 表数据
因此考虑自定义特征抽取方案,根据标签优先级策略配置抽取策略,既能做到成本可控又能做到满足时效性。
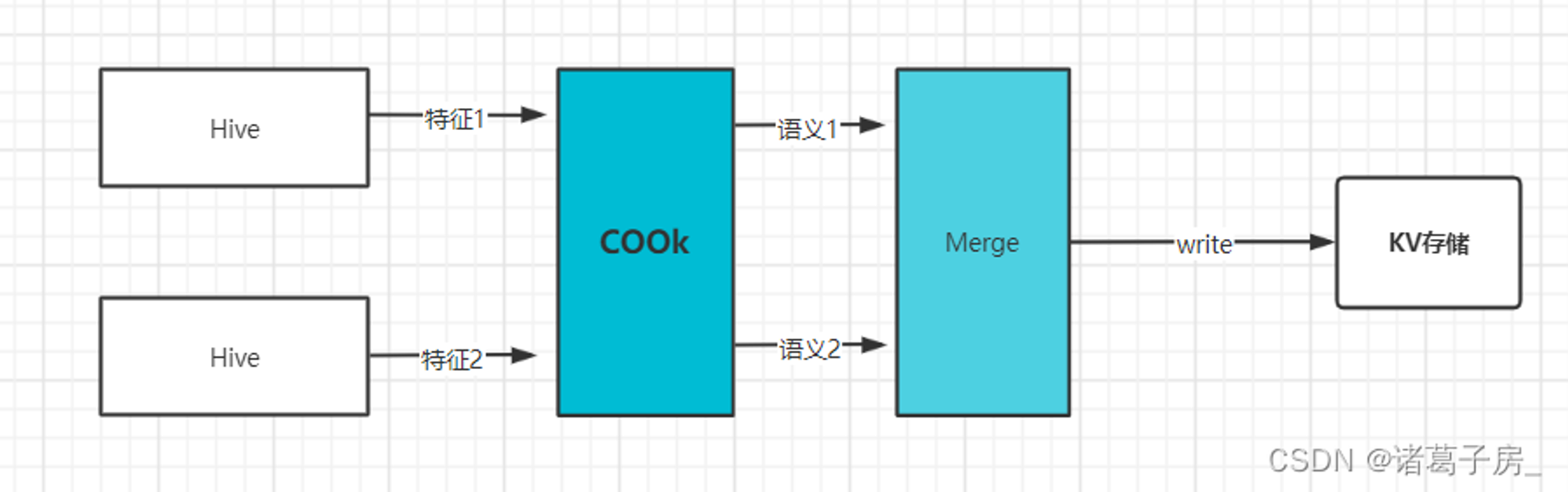
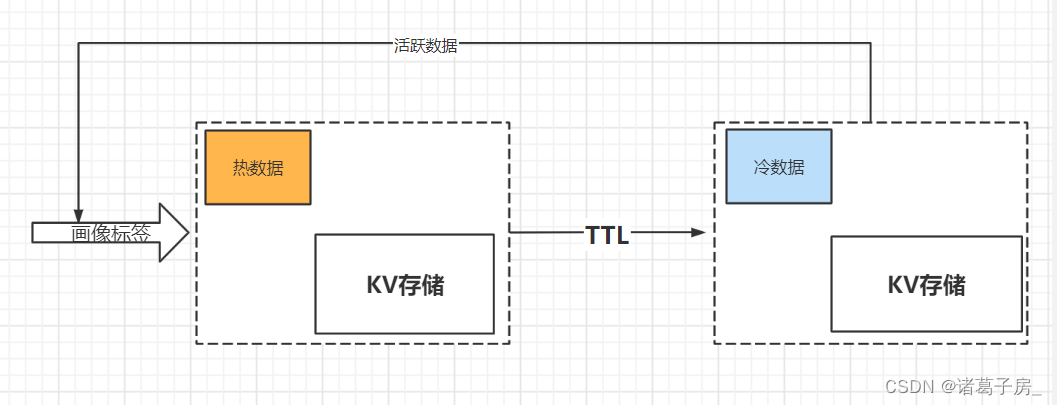
d.冷热数据分级存储
热数据考虑用更好的硬件设备进行存储(SSD、独立集群等)、冷数据考虑用一般的硬件设备进行存储(HHD、公共集群)
- 作者:诸葛子房
- 链接:https://zgzf.online/article/18fb78ef-6e0f-4506-a5cc-b480b7d8e6fb
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
